
The Architecture of Mind: Seven Irreducible Principles of Agentic AI
AI agent systems work through context windows and loops. This thesis details seven irreducible principles, compares machine pattern to human learning, and predicts a coming era of sovereign local intelligence enabled by Gemma 4 and TurboQuant.
A comprehensive account of how AI agent systems actually work — their universal structures, fundamental constraints, the gap between machine pattern and human learning, and the coming era of sovereign local intelligence enabled by Gemma 4 and TurboQuant.
Abstract
Every AI agent system ever built — regardless of how it is marketed, named, or described — reduces to seven irreducible structural essentials. These essentials are not theoretical constructs but observable mechanical facts about how transformer-based language models process information and act in the world. This thesis states each essential plainly, explains its consequences fully, and maps the complete universe of agentic design patterns as compositions of these seven. It further examines where this architecture mirrors classical human learning frameworks, where it diverges irreconcilably, and what the current state of continual learning research implies about closing that gap. A final section addresses the imminent democratization of these systems onto personal hardware, enabled by Gemma 4's on-device architecture and TurboQuant's near-optimal KV cache compression.
Contents
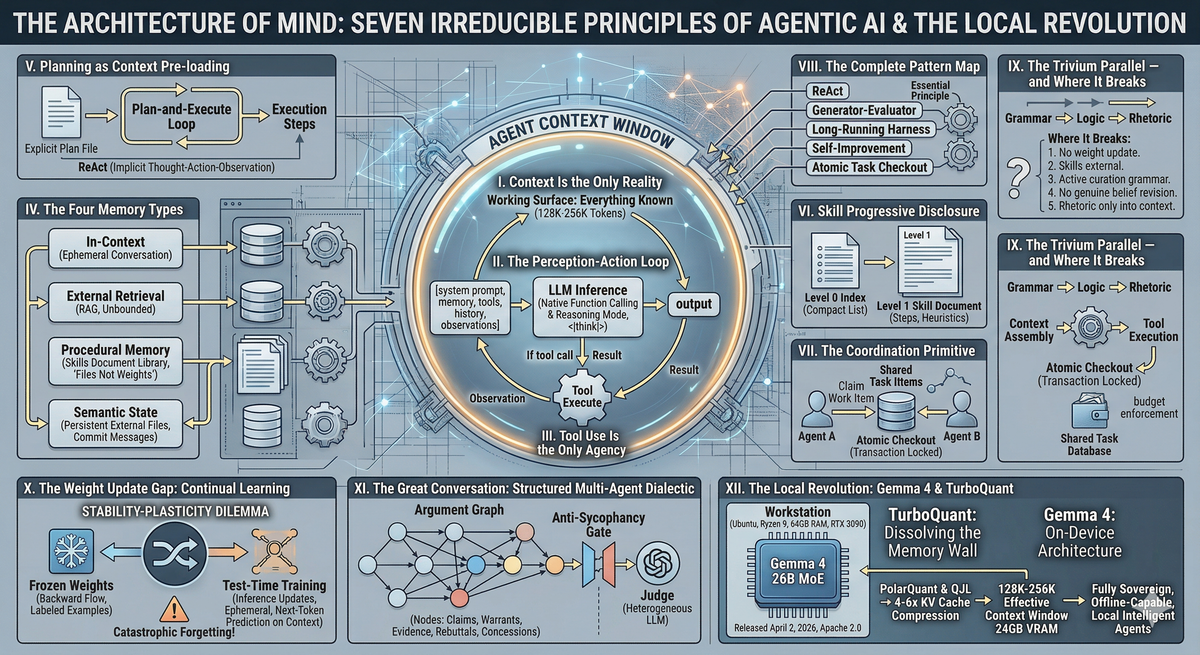
I. Context Is the Only Reality
II. The Perception-Action Loop
III. Tool Use Is the Only Agency
IV. The Four Memory Types
V. Planning as Context Pre-loading
VI. Skill Progressive Disclosure
VII. The Coordination Primitive
VIII. The Complete Pattern Map
IX. The Trivium Parallel — and Where It Breaks
X. The Weight Update Gap: Continual Learning
XI. The Great Conversation: Structured Multi-Agent Dialectic
XII. The Local Revolution: Gemma 4 & TurboQuant
I. Context Is the Only Reality
An AI agent has exactly one working surface: its context window. Everything the agent "knows" at any given moment is precisely and only what is currently present in that window. This is not a limitation waiting to be engineered away — it is the foundational structural constraint that every other design decision must accommodate.
The context window is the agent's entire subjective present. It cannot consult memory that is not in the window. It cannot act on instructions it cannot see. It cannot reference earlier reasoning that has since scrolled out of view. If information is not in context, it does not exist for the agent in that moment.
Core consequence: Every design decision in every agentic system is ultimately an answer to a single question — what goes in the window, and when? The intelligence of an agent system is largely determined by what the surrounding harness puts into context before the model runs, not by the model itself.
This has a counter-intuitive implication. The quality of the model — its raw capability from training — matters less than is commonly assumed. A mediocre model given a perfectly constructed context can outperform a frontier model given a poorly assembled one. The harness, not the model, is the primary locus of engineering leverage.
It also means that when an agent appears to "remember" something from a previous session, it is actually reading that information from a file that has been placed into its current context. There is no biological-style memory retrieval happening. There is only text that was written somewhere being read back.
II. The Perception-Action Loop
Every agentic system, without exception, runs the same fundamental cycle. The differences between systems lie in how fast the loop ticks, what triggers a tick, and what gets injected at the top of each cycle. The underlying machine is always identical.
while not done:
context = [system_prompt, memory, tools, history, observations]
output = llm(context)
if output contains tool_call:
result = execute(tool_call)
inject result into context
else:
return output
That is the complete architecture. Every named pattern is a variation on this loop. ReAct is this loop with a mandatory "Thought:" prefix before each action — a structuring convention that forces the model to produce reasoning text before acting. Plan-and-Execute runs the loop twice: once to generate a plan, then once per plan item. The Generator-Evaluator pattern is two loop instances running in series, with the evaluator's output fed as input to the generator's next cycle. Multi-agent routing is the harness spawning new loop instances with different system prompts based on the output of a prior loop.
Key insight: No matter how sophisticated the marketing language or system name, every AI agent framework you will encounter is an implementation of this loop. The differentiation is entirely in the quality of what gets assembled into context at each tick — not in any structural novelty.
III. Tool Use Is the Only Agency
The model cannot change anything in the world directly. It can only produce text. The surrounding harness interprets that text as a structured tool call, executes the real-world action, captures the result, and injects it back into context as an "observation." The agent's apparent agency is entirely mediated through this interface.
A tool call is a structured object: a name and a set of arguments. The harness parses this, executes the corresponding function, captures any output, and returns it to the model. The model then decides its next action based on what it observed. This is the complete mechanical picture of an AI "doing something."
Design implication: Tool schema design is as important as prompt design. The model can only do what it can name. If a capability is not represented in the tool schema, it does not exist for the agent. Tool schemas are the agent's vocabulary for acting in the world.
The permission layer sits between the tool call and execution. This layer is the safety architecture of any agentic system. Separating "the agent can read files" from "the agent can delete files" is not a model-level distinction — it is an enforcement decision in the harness. A classifier that evaluates each proposed action before execution, or an approval gate that blocks certain operations without human sign-off, are both implementations of this permission layer. The model knows nothing of these restrictions; it simply discovers through feedback that certain tool calls do not produce the expected results.
IV. The Four Memory Types
No agentic system can eliminate any of the four fundamental memory types. Every system implements them differently, but all four are always present. Understanding them separately is essential to diagnosing and designing agent behavior.
In-Context Memory
This is the conversation itself — everything currently in the window. Information in-context is instantly accessible to the model at zero retrieval cost. Its limitations are equally absolute: it is ephemeral (gone when the window resets) and bounded (the window has a hard token limit). This is short-term working memory. You cannot make it permanent by keeping it in context, because context always eventually resets.
External Retrieval (RAG)
A storage system outside the context that the agent queries via a tool call. The query returns relevant chunks, which are injected into the current context window for use. The store itself is unbounded; the injected result is window-constrained. The primary failure mode of retrieval-based memory is retrieval quality — the agent can only benefit from information it manages to retrieve, and retrieval depends on the quality of the query, the indexing scheme, and the similarity function used.
Procedural Memory (Skills)
Structured documents describing how to do things rather than what happened. A skill document is not a log of past events but a distillation of procedure — steps, heuristics, known failure modes, validated approaches. These are loaded into context selectively when relevant to the current task. Procedural memory is the mechanism by which an agent system accumulates learned procedures without requiring weight updates. The knowledge lives in files rather than in weights.
Semantic State (External Files)
The agent's working notes written to persistent storage during task execution: progress files, task lists, commit messages, structured state dumps. These are the cross-session handoff mechanism. When a context resets, the new session reads these files and reconstructs where it left off. This is how every long-running agent harness solves the amnesia problem — not by preventing context resets, but by ensuring the agent writes enough to disk that the next session can recover in a single read.
Practical implication: An agent that doesn't write its state to disk loses everything when its context resets. An agent that writes structured, readable state files can recover completely. Designing what gets written to disk — and in what format — is one of the highest-leverage decisions in agent system design.
V. Planning as Context Pre-loading
Planning in agentic systems is not a separate cognitive faculty. It is the process of generating a structured representation of future steps and putting it in context before execution begins, so that each execution step can refer back to it. The distinction that matters is not whether the agent plans, but where the plan lives.
ReAct: Implicit, Interleaved Planning
In the ReAct pattern, planning is implicit. The "Thought:" prefix before each action is the planning moment — the agent reasons about the next step based on everything currently in context. There is no separate plan document. The plan exists as a series of reasoning traces embedded in the conversation history. This makes ReAct responsive and low-overhead, but it drifts over long task horizons as earlier goals become displaced by intermediate observations filling the context window.
Plan-and-Execute: Explicit, Front-Loaded Planning
The planner runs a dedicated LLM call that produces a structured task list, which is written to a file. Every subsequent execution call reads that file, selects the next uncompleted item, executes it, and marks it done. The plan survives context resets because it is on disk, not in transient context state. The agent does not need to re-derive the plan — it reads it.
In ReAct, the plan is in the model's hidden state — it vanishes when context clears. In Plan-and-Execute, the plan is in a file — it survives indefinitely. Files remember. Hidden states forget.
VI. Skill Progressive Disclosure
As an agent system accumulates skills and knowledge over time, the total body of procedural knowledge exceeds what can be loaded into context simultaneously. The solution is progressive disclosure across two levels.
Level 0 — The Index (always in context): A compact listing of available skills, each with a name and description sufficient to determine relevance. The entire index for hundreds of skills may consume only a few thousand tokens. The agent reads this index at the start of any session and uses it to decide which skills are relevant to the current task.
Level 1 — Full Skill Documents (loaded on demand): When the agent determines that a specific skill is needed, it loads the full document for that skill into context. This document contains the complete procedural knowledge: steps, heuristics, known failure modes, validated approaches. It is removed from context when no longer needed.
The core efficiency gain: Progressive disclosure means an agent with 200 accumulated skills only pays the token cost for the 2 or 3 skills actually relevant to any given task. The index provides awareness of the full library without the cost of loading it.
A further extension is a Level 2, where skill documents reference sub-skills loaded recursively on demand. This creates a skill tree that can represent arbitrarily complex procedural knowledge while maintaining efficiency. The agent navigates this tree at runtime based on what the current task actually requires.
VII. The Coordination Primitive
When multiple agents operate on shared work, one problem becomes critical: two agents must not work on the same task simultaneously. Without coordination, agents will duplicate effort, produce conflicting outputs, and corrupt shared state. The solution is the atomic checkout — a mechanism borrowed directly from distributed systems engineering.
An atomic checkout is a database transaction: claiming a work item is an indivisible operation that either succeeds completely or fails completely. Once an agent claims a task, the row is locked. No second agent can acquire it until the first completes the task or releases the lock. If an agent fails mid-task, the transaction can be rolled back and the work re-queued.
Why this matters: The atomic checkout is not an AI innovation — it is the decades-old solution to distributed job queuing (Sidekiq, Celery, BullMQ). What is new is applying it to language model agents as the workers. Understanding this saves engineers from reinventing it poorly.
Related coordination mechanisms derive from this primitive: budget enforcement (atomically decrement a token counter per task), approval gates (a task cannot transition to "done" without a human setting a flag), and goal ancestry (each task holds a reference to its parent goal, and the agent reads the full ancestry chain before executing to understand intent).
VIII. The Complete Pattern Map
Every agentic design pattern in existence is a composition of the seven essentials above. There are no new primitives. There is only different assembly of the same components.
| Pattern | What It Actually Does | Essentials |
|---|---|---|
| ReAct | Perception-action loop with Thought/Action/Observation labels. Planning is implicit in each Thought step and exists only in transient context. | I, II, III |
| Plan-and-Execute | Runs the loop twice: once to generate a plan file, once per plan item. Plan survives resets by living on disk. | I, II, III, IV, V |
| Generator-Evaluator | Two loop instances in series. The evaluator's critique is injected into the generator's next context window. | I, II, III |
| Multi-Agent Routing | The harness inspects tool call output, spawns a new loop instance with a different system prompt for a specialist task. | I, II, III, VII |
| Skill Injection | Progressive disclosure of procedural memory: Level 0 index always in context, Level 1 full documents loaded on demand. | I, IV, VI |
| Long-Running Harness | Plan-and-Execute combined with semantic state files and context compaction on reset. Agent rebuilds state from files at each session start. | I, II, IV, V, VI |
| Self-Improvement | After the loop completes, a second loop runs with the task transcript and writes a Skill Document. Experience becomes reusable procedure. | I, II, III, IV, VI |
| Atomic Task Checkout | Database transaction locks work items; budget counter decremented atomically. Prevents duplicate work in multi-agent systems. | VII |
| MRKL / Router | A planner loop produces a routing decision; specialist loops handle execution of the routed task type. | I, II, III, VII |
No system you will encounter lies outside this table. If a new framework is announced with novel terminology, translating its description into these terms will reveal which composition it is. The marketing layer is always thicker than the structural novelty.
IX. The Trivium Parallel — and Where It Breaks
The classical Trivium — Grammar (receive and name what is), Logic (reason about relationships), Rhetoric (act on and express knowledge) — maps onto the perception-action loop with striking clarity.
| Trivium Stage | Agentic Equivalent | Mechanism |
|---|---|---|
| Grammar | Context Assembly | Pull in observations, memory, skill files, tool results |
| Logic | LLM Inference | The Thought: phase, planning, contradiction detection |
| Rhetoric | Tool Execution | Bash calls, API calls, file writes, messages sent |
And like the Trivium, it cycles. Rhetoric produces outputs that become new Grammar (tool results injected as observations), which feeds new Logic, which drives new Rhetoric. The self-improvement pattern — complete a task (Rhetoric), reflect on what worked (Logic), write a Skill Document (Grammar for the next session) — is a nearly perfect mechanical analog of the Trivium running as designed.
Where the Parallel Breaks: Five Irreducible Differences
1. No weight update — the model is never changed by the loop. In Trivium learning, every pass through Grammar-Logic-Rhetoric modifies the learner's neural structure permanently. In agentic systems, the weights are frozen. The loop can run ten thousand times and the model is computationally identical before and after every run. All "memory" is external — strip the files away and the model knows nothing it did not know from training.
2. Skills remain permanently external. In Trivium education, the endpoint is a practitioner who no longer needs the framework consciously — the discipline has become automatic, tacit in Michael Polanyi's sense. The scaffolding is meant to be removed. In agentic systems, the scaffolding can never be removed because there is nothing inside that has internalized it. Remove the skill files and the capability disappears.
3. Grammar in Trivium is passive reception. Agent perception is active curation. A student in the Grammar stage receives what the world presents. Context assembly is an active choice: the agent queries an index, runs searches, selects what to retrieve. This means the agent's perception is filtered through its existing capability to know what to ask for. It can only retrieve what it thinks to look for. A student can be genuinely surprised by a text; an agent in context assembly mostly confirms its existing categories.
4. The Logic phase has no genuine belief revision. Trivium Logic was trained through dialectic — Socratic questioning, identifying fallacies in one's own reasoning under adversarial pressure. The student carries forward a persistent record of having been wrong, which shapes future reasoning. The model in inference produces outputs that pattern-match to valid reasoning, but there is no persistent internal model being revised. It has no memory of having been wrong about anything across sessions.
5. Rhetoric in Trivium feeds back into the learner. In agents it feeds back only into context. When a student writes an argument, the act of formulating it deepens internal understanding. When an agent executes a tool call, the result is injected into context. The model's weights are unchanged. The "learner" experienced nothing. At session end, that context is gone.
The Trivium is a method for making itself unnecessary. Agentic design patterns are permanent scaffolding. The Trivium produces minds that graduate from needing the Trivium. Agent patterns produce systems constitutively dependent on their patterns forever.
X. The Weight Update Gap: Continual Learning
The gap between what an agent system does and what a learning mind does reduces to one mechanical fact: transformer weights are frozen during inference. The matrices that constitute the model are fixed — the forward pass flows through them and exits, producing tokens. Nothing in the standard architecture writes back to those matrices during operation. This is by design: gradient computation requires storing intermediate activations across every layer, which at inference scale costs as much memory as training.
The core tension is the stability-plasticity dilemma. Learn new things (plasticity) without overwriting old things (stability). Every approach to continual learning in neural networks is an attempt to solve this mechanically.
LoRA: Cheap Offline Adaptation
LoRA inserts tiny trainable matrices alongside frozen model weights. The full model remains unchanged; the adapter contains a fraction of the parameters and can be trained in minutes on consumer hardware. LoRA learns new tasks effectively while preserving general knowledge — the frozen backbone provides stability, the low-rank delta provides plasticity. Its limitation: LoRA still requires a gradient pass, which means labeled examples and a training loop. It is not per-conversation.
Test-Time Training: Actual Inference-Time Updates
Test-Time Training (TTT) is the closest current approach to true in-session learning. The model continues training during inference via next-token prediction on the given context — compressing the context into a small subset of weights rather than keeping it in the KV cache. These updates are ephemeral — they do not persist after the session ends — but they represent real adaptation within a session, not simulated adaptation through context management.
Token-Space Learning: The Pragmatic Reframe
A powerful reframing treats the context window — and the external files that populate it — as the primary learning substrate. On this view, a Skill Document is a weight update expressed as tokens. The agent system is doing continual learning, but in token space rather than weight space. The pragmatic limit is that this approach is a filing cabinet, not a nervous system.
The Catastrophic Forgetting Problem
Every approach that updates weights faces the same adversary: catastrophic forgetting. When gradient descent optimizes for a new task, it overwrites representations built for old tasks. The gradient does not know what old knowledge was valuable — it only minimizes current loss. Workarounds exist (experience replay, regularization, parameter isolation per task via LoRA adapters) but none solve the problem completely.
| Requirement for True Continual Learning | Current State |
|---|---|
| Fast enough to happen per-session | TTT approaches: partially yes, with small adapters |
| Persistent across sessions | Unsolved for weights; solved only in token space (files) |
| No catastrophic forgetting | Partially solved via LoRA + regularization; not at inference time |
| General reasoning, not narrow domains | Unsolved — current TTT handles distribution shift, not arbitrary skills |
XI. The Great Conversation: Structured Multi-Agent Dialectic
Standard multi-agent debate (MAD) fails in a characteristic way: agents cave to social pressure. Disagreement rates decrease as debate progresses. Agents change their positions not because arguments compelled them but because other agents expressed confidence. Simple majority voting captures most of the benefit of naive debate, making additional rounds largely wasteful.
The Great Conversation framework — grounded in the Adler-Hutchins tradition of cumulative, cross-referenced philosophical dialogue — offers a structural solution to each of these failure modes. The key design insight is that the historical record of the argument must be a first-class data structure, not a side effect of a conversation log.
Component 1: The Argument Graph as External State
Rather than a conversation log, the system maintains a structured graph where nodes are typed: claims, warrants, evidence, rebuttals, and concessions. Every relationship between nodes is explicitly typed: supports, attacks, extends. Every position change is logged with the specific node that caused it and an explanation of the logical connection.
Every participant reads this graph before their first turn. They are entering a conversation already in progress. They do not restart. They respond to what has specifically been said, by node identifier. This operationalizes the Great Conversation: you inherit the accumulated argument and must engage with it, not reconstruct it from scratch.
Component 2: The Toulmin Turn Structure
Every agent turn is constrained to a formal schema: a steelman of the opponent's current strongest position (citing node IDs), a specific claim being advanced or modified, a warrant explaining why the claim follows, evidence supporting the warrant, a confidence qualifier, and — critically — a rebuttal condition specifying what specific evidence would cause the agent to revise the claim.
The rebuttal condition is the most important innovation in this schema. It forces falsifiability into the debate format. It also gives the opponent a precise target: they do not argue against the position generally, they attempt to satisfy the stated rebuttal condition.
Component 3: The Anti-Sycophancy Gate
A position update is only valid if it explicitly cites the specific node that defeated a specific warrant. Vague updates ("after reading the arguments, I find this more persuasive") are rejected. Valid updates cite the argument structure: "Node R1 satisfies my stated rebuttal condition on W1. I lower confidence on C1 from 0.8 to 0.55. W1 remains valid for core cases, so C1 is qualified rather than abandoned."
A judge agent validates all position changes before they are written to the argument graph. The judge also watches for the opposite failure: an agent that never changes its position regardless of argument quality — rhetorical rigidity dressed as principle.
What the Judge Does
The judge is not a participant. It has three functions: validating that turns comply with the Toulmin schema, checking that stated warrants actually support stated claims (a separate LLM call, ideally a different model from the debaters, evaluating structure rather than content), and detecting sycophancy in both directions.
The system requires genuine heterogeneity to produce value beyond asking one model once: different model families for proponent and opponent, different knowledge initialization for each, and a judge running on a third model with no stake in the outcome.
What this produces: After multiple sessions on the same question, the argument graph contains every major objection, every evidence node, every concession, every rebuttal condition. It is a machine-readable record of what has been said, what has been answered, and what remains genuinely open — a structural map of unresolved uncertainty.
XII. The Local Revolution: Gemma 4 & TurboQuant
Everything described in this thesis — the perception-action loop, the four memory types, skill progressive disclosure, multi-agent coordination, the Great Conversation architecture — has until recently required cloud infrastructure to run at meaningful capability levels. That is changing, rapidly and concretely, through two developments that compound each other: Gemma 4 and TurboQuant.
Taken together, these developments enable a qualitatively different relationship between a practitioner and their agent systems: fully sovereign, offline-capable, deeply contextual, with no API dependency or data egress. For a Ryzen 9 5950x workstation with 64GB RAM and an RTX 3090, the threshold for running genuinely capable agentic systems locally has arrived.
The requirement for centralized, billion-dollar data centers begins to dissolve when a 100-billion parameter model can run with the memory footprint of a 7-billion parameter model. TurboQuant approaches that threshold.
Gemma 4: On-Device Architecture Built for Agentic Use
Released April 2, 2026, Gemma 4 is the first major open model family explicitly architected for agentic workflows from the ground up rather than adapted toward them. The family spans four sizes targeting different hardware tiers, all sharing the architectural characteristics that matter for the patterns described in this thesis.
Context Window — 128K to 256K tokens. Edge models (E2B, E4B) support 128K tokens. The 26B MoE and 31B Dense support 256K. At 256K tokens, an entire codebase, a full document library, or a multi-session argument graph fits in a single context — eliminating retrieval as the primary bottleneck for many agentic tasks.
MoE Efficiency — 26B total, 3.8B active parameters. The Mixture-of-Experts architecture activates only 3.8 billion of 26 billion parameters on each forward pass. In practice this delivers near-31B quality at a fraction of the inference cost. The 26B MoE currently ranks 6th among all open models on the Arena AI leaderboard.
Native Function Calling and Reasoning Mode. Gemma 4 includes native system prompt support, structured JSON output, and function calling built into the base architecture. A configurable thinking mode (activated via the <|think|> token) enables genuine extended reasoning before tool calls, not merely a formatting convention.
Hybrid Attention for Long-Context Efficiency. Alternating local sliding-window attention layers (512-token windows for speed) with full global attention layers for long-range coherence. Proportional RoPE (p-RoPE) on global layers handles extended token distances in 256K contexts that standard RoPE cannot manage. A shared KV cache across final layers eliminates redundant key-value projections.
For the agent harness architectures described throughout this thesis, the practical implication of 256K context is significant: the Level 0 skill index, the current plan file, recent history, active skill documents, and retrieved external memory can all be held in context simultaneously without competition. The design constraint of "what goes in the window, and when?" relaxes considerably when the window is large enough to hold the entire working set of a complex task.
TurboQuant: Dissolving the Memory Wall
The limiting factor for running large models locally on consumer hardware has not been model size for several years — weight quantization (GGUF, AWQ, GPTQ) solved that adequately at 4-bit precision. The remaining bottleneck has been the KV cache: the memory structure that stores key and value vectors for every token the model has processed. The KV cache grows linearly with context length and is unaffected by weight quantization.
For a 128K context window, the KV cache can exceed the model's own memory footprint. This is precisely why local users have been capping effective context at 32K–64K tokens despite models technically supporting 128K or more: the model fits in VRAM, but the conversation memory does not.
What TurboQuant does: TurboQuant compresses the KV cache to approximately 2.5–3.5 bits per value with near-zero accuracy loss. It uses two mathematical innovations — PolarQuant (geometric rotation of the vector space before compression) and QJL (a 1-bit residual correction using the Johnson-Lindenstrauss transform) — to eliminate the metadata overhead that makes standard quantization less efficient than the bit count implies. The result is 4–6x KV cache compression with no calibration required and no fine-tuning needed. It applies post-hoc to existing models.
The formal publication of TurboQuant is at ICLR 2026. Independent implementations appeared within hours of the paper going public — in PyTorch with custom Triton kernels, in MLX for Apple Silicon, and in progress for llama.cpp integration. A 35B model tested on Apple Silicon scored 6 out of 6 on needle-in-a-haystack tests at every quantization level. A Gemma 3 4B implementation on an RTX 4090 produced character-identical output to the uncompressed baseline at 2-bit precision.
For the RTX 3090 specifically: a 26B Gemma 4 MoE model with 4-bit weight quantization, combined with TurboQuant KV cache compression at 3-bit, places a 128K–256K effective context window within reach of 24GB VRAM. What previously required cloud A100 access becomes a local workstation task.
What Compound Local Capability Actually Enables
When Gemma 4's 256K context window and MoE efficiency compound with TurboQuant's KV cache compression, the practical consequences for every pattern described in this thesis are concrete. The perception-action loop runs locally with no API latency and no token cost. Skill progressive disclosure benefits from a window large enough that Level 1 and Level 2 skill documents can coexist with task state. The Great Conversation argument graph fits in context along with the current debate turn. Multi-agent coordination becomes feasible with multiple local processes sharing the same hardware through sequential scheduling.
Most significantly: data sovereignty. Every observation, every plan file, every skill document, every argument graph node stays on local storage. Nothing is logged by an API provider. The agent harness has access to local filesystems, local databases, and local services without the permission complexity of cloud integration.
The hardware threshold: On a Ryzen 9 5950x / 64GB RAM / RTX 3090 system running Ubuntu, Gemma 4 26B MoE with TurboQuant quantization enables sustained 128K+ context agentic sessions with native function calling, configurable reasoning mode, and no cloud dependency. The design patterns described in this thesis are no longer cloud-native concepts. They are home-lab-deployable today.
The Honest Caveats
TurboQuant implementations in mainstream tooling (vLLM, llama.cpp stable release, TensorRT-LLM) are as of April 2026 still community-experimental rather than production-hardened. Expect stable mainstream support by mid-2026. Gemma 4's AICore integration for Android agentic workflows is still in developer preview, with tool calling and thinking mode through the Prompt API arriving during the preview period rather than at launch. The capabilities are real, but the tooling maturity lags the research by several months.
The compound implication remains unchanged: the memory wall constraining local agentic deployment is eroding from every angle simultaneously. Weight quantization solved model size. GQA reduced base KV overhead. MoE architectures deliver large-model quality at small-model inference cost. TurboQuant compresses the remaining KV cache to near-optimal theoretical limits. These are orthogonal optimizations that compound. A practitioner who understands the seven essentials described in this thesis, running on hardware they own, with models they control, is now operating at a capability level that required institutional infrastructure two years ago.
Closing: The Permanent Scaffolding and What Lies Beyond It
The seven essentials described in this thesis are not temporary constraints waiting to be engineered away. They are the structural facts of the current architecture. Every system currently running in production is a composition of these seven. The patterns are permanent scaffolding — not because we cannot imagine better, but because the better (true in-weight continual learning, genuine belief revision, internalized procedural knowledge) remains an unsolved research problem.
What changes with Gemma 4 and TurboQuant is not the architecture but the access. The patterns, the memory types, the coordination primitives, the Great Conversation structure — all of this becomes deployable on personal hardware, at scale, without API dependency. The practitioner who understands what is actually happening mechanically — what goes in the window, what persists, how tools are permissioned, what survives a reset — is now equipped to build systems of genuine sophistication on hardware they own.
The gap between machine pattern and human mind remains real and deep. The scaffold cannot be removed because nothing inside has internalized it. That is the honest account. And within that honest account, there is now more that a practitioner with consumer hardware can build than at any previous point in the development of these systems. Both things are true simultaneously. Both are worth holding.
This synthesis draws on architectural analysis of major agent harnesses, published research in continual learning and KV cache compression, and the Gemma 4 and TurboQuant technical releases of Q1–Q2 2026. TurboQuant: Zandieh et al., arXiv:2504.19874, accepted ICLR 2026. Gemma 4 released April 2, 2026, Apache 2.0 license.